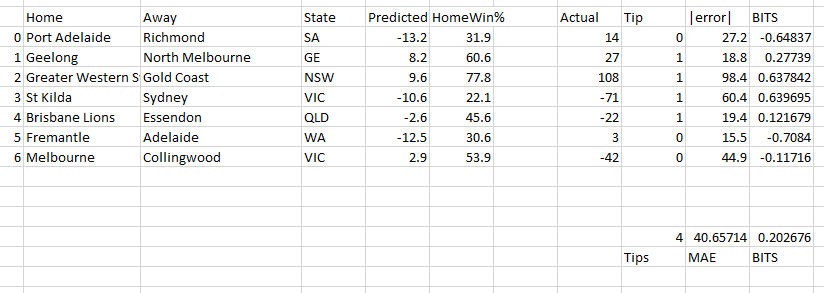
Everyone has done a piece on home ground advantage, and now it’s my turn. This will hopefully be one of a series of posts, the next one or two will hopefully complete this module of my model and hopefully not be a complete waste of time.
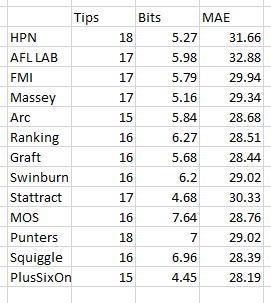
In the development of my model, figuring out how to best quantify home ground advantage was difficult to approach. At the moment, I use a very simple measure to account for “team travel”, and use adjustments for each team and player as to how they play at home or away given their upcoming fixture (i.e. Scott Pendlebury would be expected to contribute less to a Collingwood away game as his recent away form is poor.)
I have identified seven possible predictors of home ground advantage, and how each of them may be quantified:
- The actual venue itself
- “Morale” from playing to a home crowd (?)
- “Favouritism” from the umpires (free kick differential)
- Familiarity with the ground/facilities (count of previous games played for each team)
- Not having to travel far (travel time for each team)
- Players sleeping at normal home (boolean for each team)
- How often they travel (interstate games per season)
Most of these are measurable from available data on past games, and predictable through the fixture.
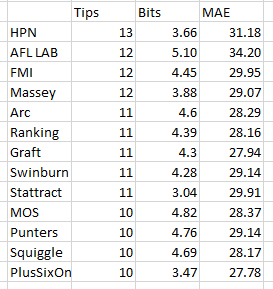
Other models deal with HGA by applying a correction to the margin in the form of a flat number (Matter of Stats), or a percentage (possibly different for each venue?), or consideration of some of the above to get a HGA variable into their model (i.e. FiguringFooty, The Arc). Some just ignore it altogether and do pretty well (HPN).
In this post I will investigate the first 3 of these identified predictors and I will investigate their usefulness (or lack thereof). Following this a general discussion of the difficulties of distilling HGA out of existing data.
***
First, let’s have a look at some of the available data to explore some of the elements of HGA. Here I am using data from 2011 onwards. I could use data from further back but I like to keep things modern.
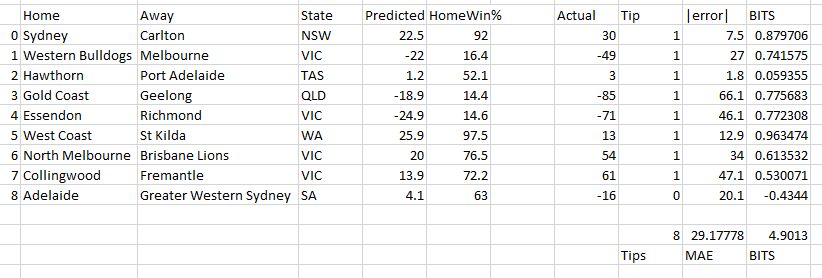
A broad viewing of game result data shows distinct differences between many of the common AFL venues. For each ground, the distribution of the margin and total points is presented in the following figure.
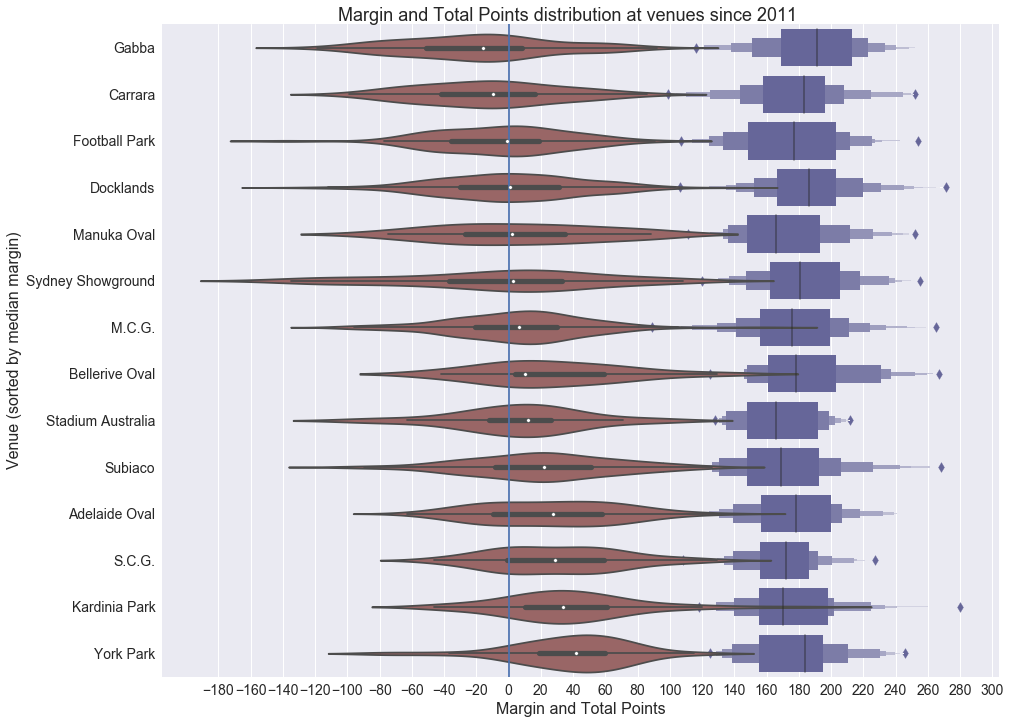
There’s a lot to unpack here. I’ve only included venues with more than 25 games played in the period or you get some real outliers (Jiangwan Stadium, for example). For clarification, a positive margin indicates a home victory.
While not a huge focus of mine at this stage, the total points scored does show variation, indicating it may be better to consider a percentage HGA bonus rather than a flat points bonus.
On the surface, the ‘Gabba is often a disadvantage to the home team; but that home team is Brisbane, who haven’t cracked the finals since 2009. York Park provides a median 42 point advantage; but Hawthorn mainly play there and they’ve been rather good. Without discounting individual margins by the strengths of the teams on the day, it’s difficult to tell whether each ground has an independent HGA, a common HGA, or no HGA at all! I’m keeping (1) as a possible predictor at the moment until more analysis can be done.
The more interesting data, perhaps, is that of the Melbourne venues MCG and Docklands. Firstly, the large number of games played there gives a better set of data to examine. Secondly, all Melbourne teams play home games there so on average, there should be less bias towards “how good” the home team is. If we filter games to Melbourne teams vs Melbourne teams (i.e. not Geelong) at the MCG and Docklands, things look very even!
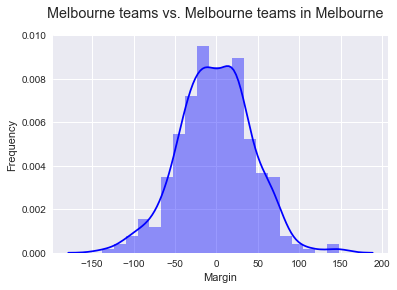
For this data (360 games), the mean is -0.825 and the median margin is -1. There is no perceptible skewness in the distribution. From this sample, it cannot be said that there is an advantage (
***
Let’s now consider another common gripe about Home Ground Advantage, that of the perceived favouritism of umpiring decisions. My personal view is that the free kick differential is not indicative of favouritism, and more indicative of player indiscipline. Possibly this is a mental effect from playing away from home! Without reviewing every decision and classifying each as a “justified” free kick or an “umpiring error”, it is not possible to comment on favouritism as a concept. Nevertheless, let us look at whether teams get more free kicks at home, and if this results in more wins.
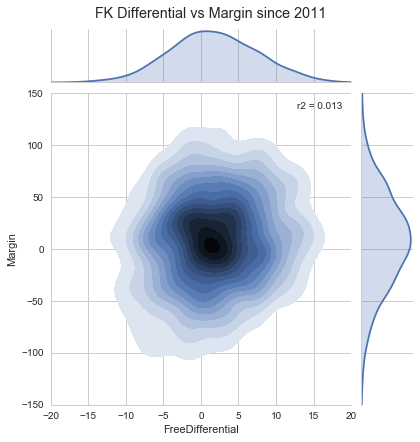
This is the data from all games since 2011. In the central plot, a darker colour means a higher frequency of data. On the right-hand side is the distribution of margins (positive means a home victory) and on the top is the distribution of free kick differential (positive means more home free kicks).
Firstly, home teams DO get more free kicks (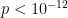
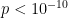
On the face of it you could easily make the connection that free kick differential correlates with the margin. The central plot tells the story that this is simply not true. The free kick differential is not a good predictor of the margin. There are many games where the free kick differential and margin have the opposite sign, almost as many as where they have the same sign. Just beacuse I’m playing around with visualisations at the moment, here is a plot of the Inside 50s differential vs. the Margin:
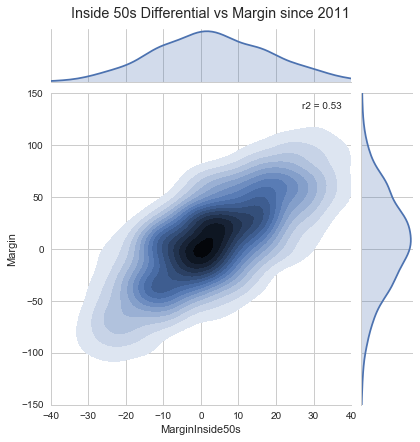
This is a much better predictor.
I aim to look at some of the other predictors (4-7) in a later piece after I have done some more work on it. For the moment I’m just going to consider some thoughts on how to proceed after doing this work!
***
The Scale of the Problem
There are a number of challenges facing this analysis. Firstly, let us assume the following model for predicting the outcome of a match
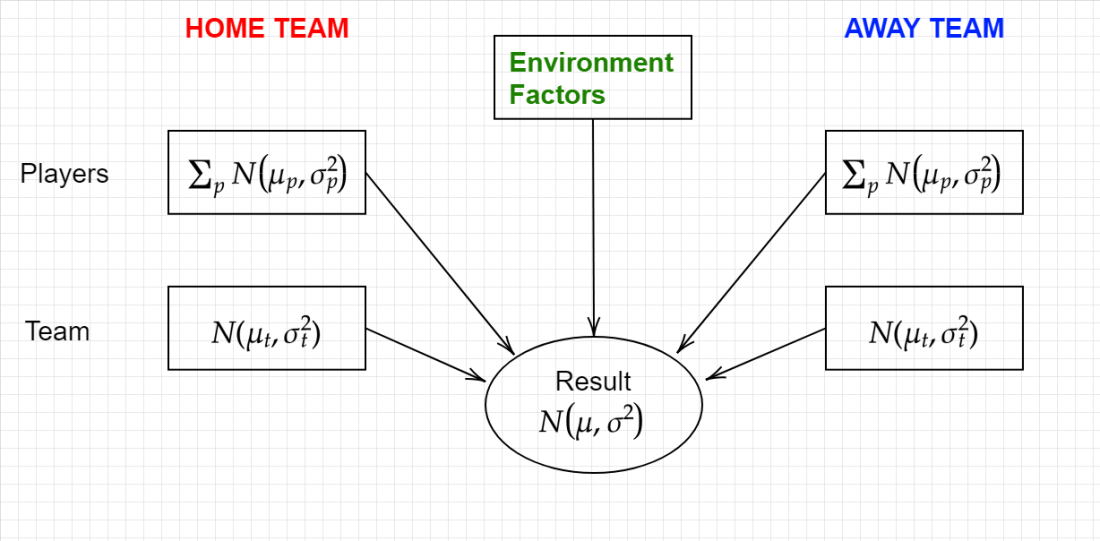
The team performance and player performance of each team may be predicted using their form. Environment factors include things such as HGA, the weather, and other possible factors such as if a team is coming off a short break or the bye.
To get a good measure for HGA one would need to dial out, for each past game, the effect of team performance, player performance, and non-HGA environment factors to work out an adjusted “game HGA”. From this measure, a model with each of the relevant HGA “predictors” identified could be matched.
Without doing any of the quantitative measurements, it’s easy to argue why this is going to at least be very difficult. The HGA is prevalent in the team and player performance too. Although this can be predicted from past data, this means that the full effect of HGA will be difficult to sum up. Furthermore, after removing player and team performance bias, the question remains on how to account for other environmental factors. It will likely be necessary to fit all environmental predictors (HGA, weather, etc.) simultaneously.
Then there are other problems. Is it possible that each venue has its own HGA independent of other factors? Does this change over time, i.e. how does stadium development affect this?
While I have a decent grasp on team and player performance, my model currently neglects to take weather into account (more on this in a future post I hope) and already includes HGA bias for the team and player performance. I am not in a position to attempt this quantitatively at this stage.
Nevertheless, I have some better ideas of how to proceed with this difficult problem. Firstly, I need to use player and team performance to quantify a residual “environmental” margin for each game (encompassing HGA, weather effects and noise), then examine the effects of venue, travel time, days between matches, and determine a way of describing the effect of weather.
It’s easy to see why a simple measure of HGA is attractive.
To be continued.
-Adam

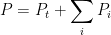
 is a sum of team-related performance
is a sum of team-related performance 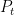 and the total contribution from each of the players
and the total contribution from each of the players  .
.