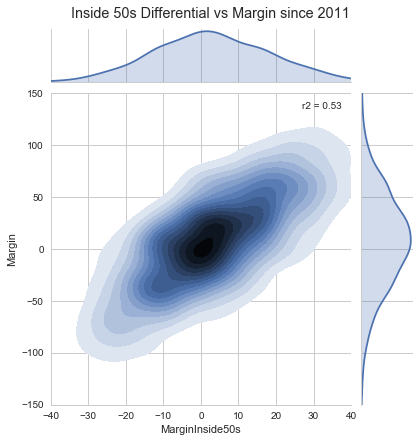
As part of my previous piece that began to explore elements of home ground advantage (HGA), I identified that in order to be able to isolate the effects of HGA, one would need to first account for player performance, team performance and other environmental factors.
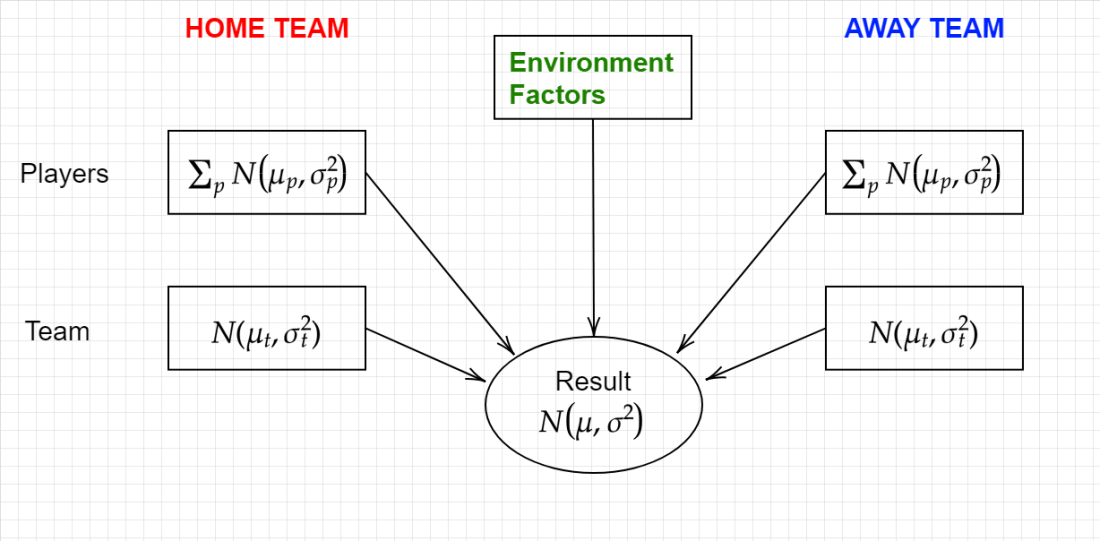
As discussed in the previous piece, the environmental factors consist of of many measurable and immeasurable modifiers that affect the outcome of a game. This could include home ground advantage, the weather, if a team is coming off a short break, if a team has traveled a lot lately, if players are carrying injuries, if there’s a player milestone, if it’s a “rivalry” game, and the list goes on. Some of these are easier to look at than others. In time I hope to investigate and, if necessary, account for all of these factors.
In this piece, I’m going to focus on the weather conditions and how they affect the outcome. Like my previous piece, there are more questions than answers at the moment. Nevertheless, I hope you find this thought-provoking!
Wet Weather Football
Playing in the wet is a different game altogether. The physics of the game changes. The ball is slippery; making slick handballs too slick, contested marks rare and ground ball pickups difficult. The players are slippery; tackles don’t stick as well. The slippery ground however makes the ball bounce a little straighter so there are benefits to exploit, but I digress. It’s easy to argue that wet weather affects the game, but how can we measure it?
“Now over to Tony Greig at the weather wall”
The lads that manage fitzRoy (a magnificent package for those interested in a leg-up start in probing AFL stats) include some BoM rainfall data for each match in the 2017 season; which seems like a good place to start. From BoM I scraped historical rainfall data from the nearest weather stations to each AFL ground and attached the game day’s rainfall to each game from 2011 onwards. There were plenty of gaps in the data, from 1563 games I ended up with 953 records. The standard stereotype of wet weather football is low scores. Below I present a set of histograms of the total points scored in matches with different daily rainfalls.
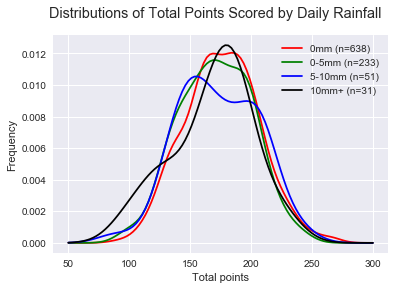
Wow! Either rain has little effect on the total points scored, or these daily rainfall figures do not represent the conditions at the football ground during the match.
In Round 5, 2015, the Gold Coast local weather station recorded a daily rainfall aggregate of 132mm after 9am. By 4:35pm when the Suns took on the Lions, the ground was seemingly dry and there was no report of wet/slippery weather and scoring certainly wasn’t affected. These types of anomalies (I’m sure there are many) make the daily rainfall near the ground a poor measure of the actual effect of the rain on the game.
While this annoyed me a bit; quite a bit of time was spent scraping and organising the rainfall data, it did illuminate a possible next step. As mentioned above, the match report did not mention the weather or the conditions being a problem. Maybe parsing match reports for keywords could work! This year in Round 10, Geelong took on Carlton at Kardinia Park. The game was low scoring, the daily recorded rainfall was nil, but the match report mentions the “dewy” conditions.
So this seems like a sensible option; if the game conditions are going to be mentioned anywhere it will be in the match report — if the conditions affected the game. I doubt this will be absolutely error-free but I’ll wager it will more accurate than rainfall data.
How Loquacious are Footy Journalists?
The actual task of parsing every match report for keywords is formidable. It can be done, I’m sure, with a big enough vocabulary and suitable processing strategy. I’m currently in the stages of sampling match reports and manually finding a suitable set of keywords for different conditions. As this task sucks it’s happening very slowly. While I work up the enthusiasm to tackle this, another question popped into my thought process.
How do you quantify the conditions?
One could be as descriptive as they wanted with the conditions, specifying how much rain there was, if it was windy (and if it’s prevailing or swirly), if it’s dewy, if it’s hot, humid, etc. The more information you use will likely lead to better model fitting to the existing data. This presents problems:
- for many combinations of conditions there will be a paucity of data.
- if your parsing of match reports is wrong (or the journo was exaggerating to forgive their team’s performance!), you’re trying to fit a sophisticated model with rubbish data.
- if predicting future results is your goal, you need to know exactly what the conditions are going to be to get a good prediction using your model.
At the other extreme, the most simple way to quantify conditions would be to attach a binary variable to each match: Is it weather-affected? Yes/No. This is as fool-proof as you can get, any keyword showing up in the match report will trigger it, and you can be fairly certain a day or two in advance whether weather will affect a game.
As I like to do in almost all areas of my life, I look at the extremes and always end up somewhere between them. In this case, I plan to parse match reports for keywords relating to rain/dew, wind, and heat/humidity separately. I will be giving each game a nominal score from say, 0-10, a measure of the strength of the condition. This will give me the option of implementing each weather type as a binary (yes/no) or ordinal (0-10), or just a single “is it weather-affected?” binary variable.
It’s more than just a number
While I think even the simplest approach outlined above will give a decent idea of how the weather will affect the margin/total points — certainly better than the rainfall data I hope! — it’s about more than just that. While the current aim of my modelling is to improve my understanding of the available stats through predicting future results, there are also more interesting questions I hope to be in a position to answer in the future.
Wet weather football, what is it all about? What type of team does it best? My model uses a number of different variables to measure each player/team’s performance:
- Scoring,
- uncontested play,
- contested play,
- ball movement/delivery,
- defence
- experience
- air (ruck and contested marking)
Including all of these measures; along with weather measures, has the potential of elucidating what skills, team balance and game plan work in different conditions.
Cheers for now.
-Adam
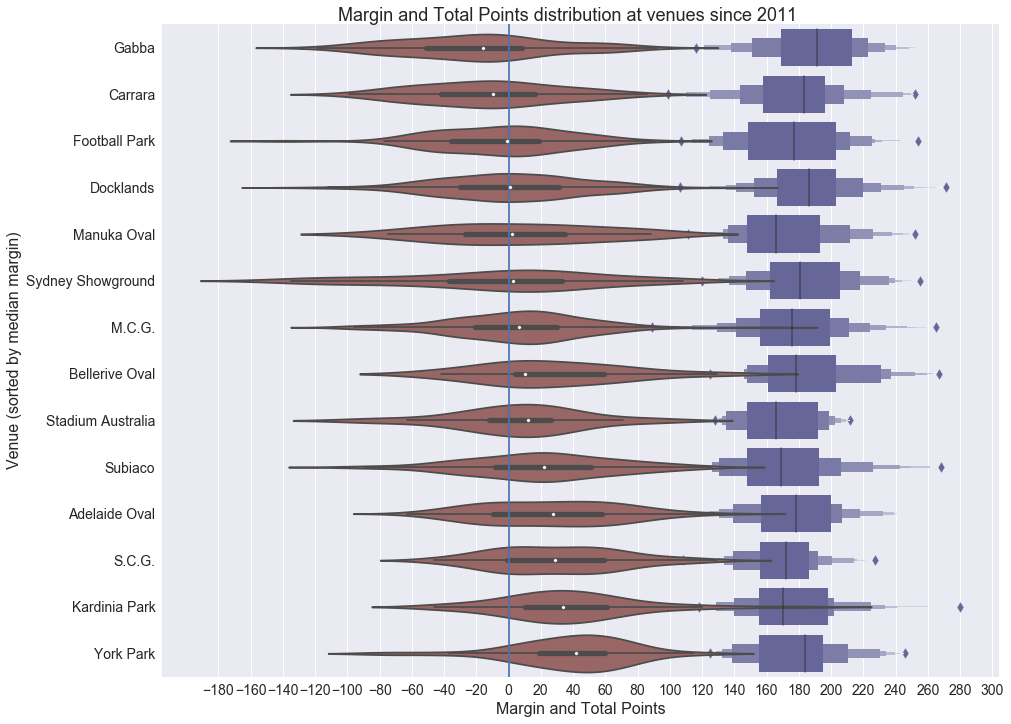
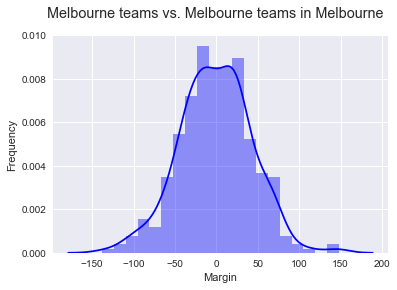
 ). But is this actually important? The only differences for the home and away team in this set of games is the change rooms they use (I think?). I suspect there may be a larger ratio of home fans in attendance but given the capacity of the grounds, not many fans would be locked out. Either way it makes no perceptible difference. At least for moderate differences in crowd it’s probably acceptable to dismiss (2) as a possible predictor.
). But is this actually important? The only differences for the home and away team in this set of games is the change rooms they use (I think?). I suspect there may be a larger ratio of home fans in attendance but given the capacity of the grounds, not many fans would be locked out. Either way it makes no perceptible difference. At least for moderate differences in crowd it’s probably acceptable to dismiss (2) as a possible predictor.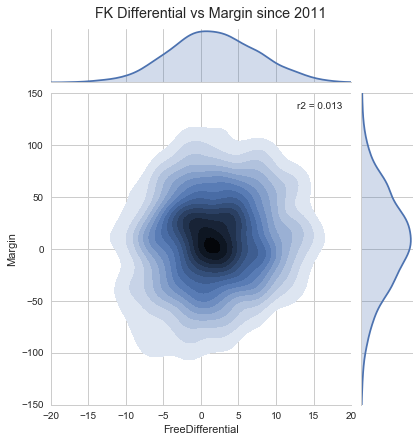
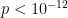 ). From the 1554 samples, on average, home sides get 1.70 more free kicks. And of course, home teams score more than their opposition, (
). From the 1554 samples, on average, home sides get 1.70 more free kicks. And of course, home teams score more than their opposition, (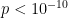 ), 7.97 points on average.
), 7.97 points on average.